
June 13, 2026
Similarity-First EEAT Rewrite, 11-Tier Scoring & Production Launch
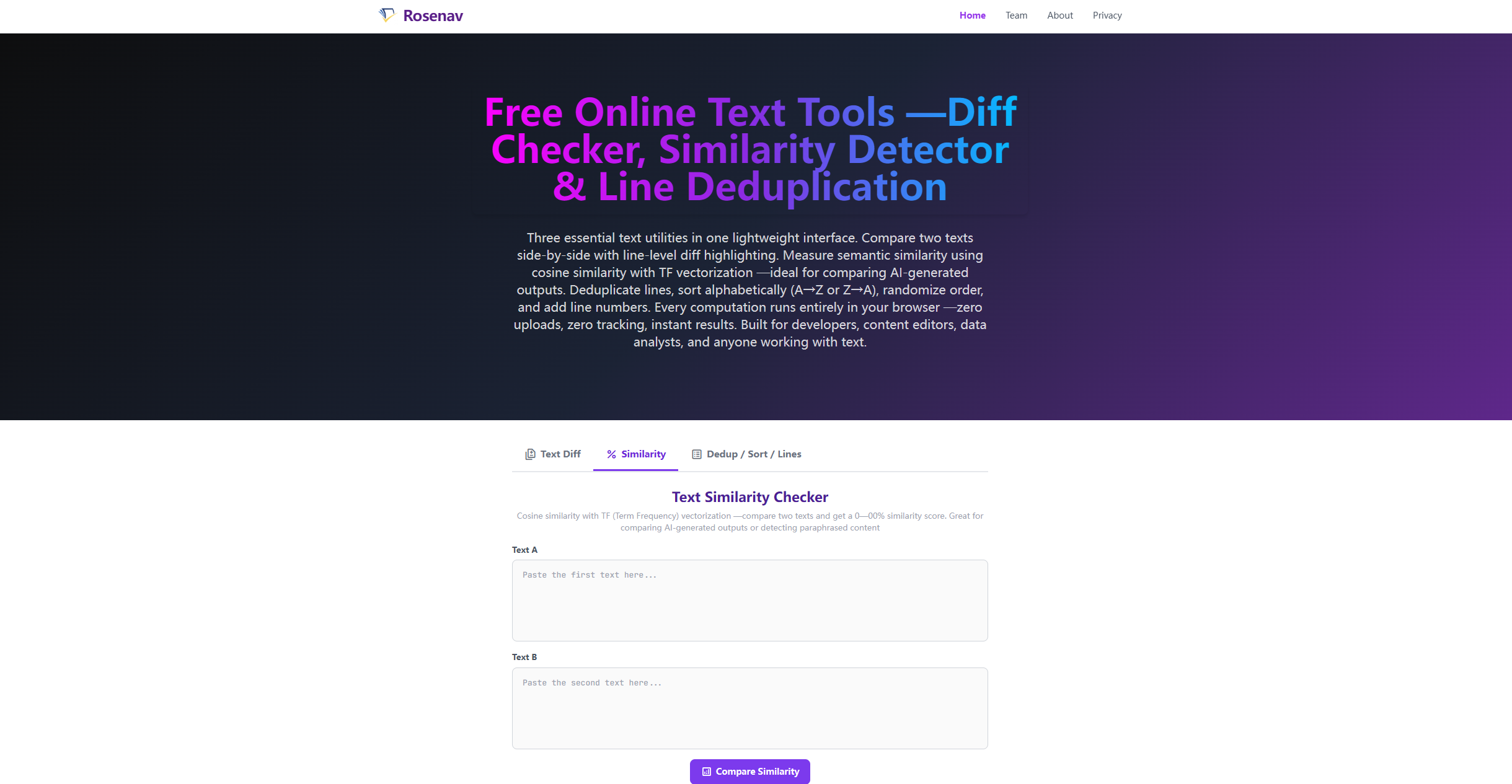
EEAT Homepage Rewrite — Similarity as Primary Feature
The homepage underwent a complete EEAT-compliant content rewrite, repositioning the text similarity checker as the primary feature with cosine diff and line operations as secondary tools. The Title tag was restructured to "Free Online Text Similarity Checker & Cosine Similarity Calculator — Compare Two Texts | Rosenav", the Meta Description expanded to 157 characters covering the 0-100% scoring system and 11-tier descriptions, and the H1 refined to "Free Online Text Similarity Checker — Compare Two Texts & Get 0-100% Overlap Scores." The On This Page navigation tree was reordered to Similarity → Diff → Dedup → Privacy → FAQ. A new H3 section, "Understanding Your Similarity Score — The 11-Tier Description System," was added to the Similarity SEO block, listing all 11 qualitative tiers from "Identical vocabulary distribution" at 100% down to "Completely unrelated" at 0-9%. The FAQ was expanded from 8 to 9 items with a new lead question: "How do I use the text similarity checker to compare two texts?" — providing a step-by-step walkthrough. All FAQ numbering was re-indexed (faq-1 through faq-9) and the JSON-LD FAQPage block was synchronized with matching Q&A entries.
11-Tier Similarity Description System — Granular Scoring Feedback
The similarity checker's qualitative description system was refined from 5 coarse tiers to 11 granular tiers at 10-percentage-point intervals. Each tier now maps to a specific English description generated client-side by computeSimilarity() in text-tools.js: 100% → "Identical vocabulary distribution," 90-99% → "Nearly identical," 80-89% → "Strong similarity," 70-79% → "High similarity," 60-69% → "Noticeable similarity," 50-59% → "Moderate similarity," 40-49% → "Moderately different," 30-39% → "Mostly different," 20-29% → "Largely dissimilar," 10-19% → "Almost entirely different," and 0-9% → "Completely unrelated." The tier system is documented in full on the homepage's new H3-4 section, bridging the gap between raw percentage scores and actionable interpretation. The color-coded progress bar tiers were preserved (≥90% sim-very-high green, ≥70% sim-high, ≥40% sim-medium, else sim-low red).
WebApplication JSON-LD Expansion — Keyword-Rich alternateName Array
The WebApplication structured data block was updated to reflect the similarity-first positioning. The alternateName array expanded from 5 to 7 entries: "Rosenav," "Text Similarity Checker," "Cosine Similarity Calculator," "Text Overlap Checker," "Text Diff Checker," "Line Deduplication Tool," and "Online Text Tools." The description field was rewritten to lead with the similarity checker before mentioning diff and dedup tools. The FAQPage JSON-LD was resynchronized to match the expanded 9-item HTML FAQ, maintaining the required structured-data-to-visible-content parity. The Organization and BreadcrumbList JSON-LD blocks were locked and unchanged per the 345tool satellite site matrix policy.
Production Deployment — Nginx, Sitemap, GA4 & Final Configuration
The rosenav.com.nginx.conf server block was finalized with production-grade settings: proper server_name rosenav.com www.rosenav.com, TLS/SSL well-known paths, gzip compression for CSS/JS assets, and PHP-FPM upstream integration. Google Analytics 4 was activated and embedded in header.php, enabling page-view and session tracking — collecting only anonymized page-level analytics, never textarea input data. The XML sitemap was regenerated with all canonical URLs locked to rosenav.com, and robots.txt was updated with production sitemap reference and crawl rules. The CSS delivery remained optimized as a single combined.css file. All structured data JSON-LD blocks across index, about, privacy, and team pages were verified for schema validity and cross-page consistency. The JavaScript cache version was incremented to text-tools.js?v=5 for cache-busting.
June 10, 2026
Engine Audit, escapeHtml Fix & Mode Height Synchronization
escapeHtml Bugfix — Entity Encoding No-Op Discovery & PHP-Based Repair
A critical bug was discovered during a full engine audit: the escapeHtml() function in text-tools.js was a complete no-op. All four .replace() calls replaced characters with themselves: '&' with '&', '<' with '<', etc., due to a copy-paste error where the replacement string was identical to the search string. This meant HTML special characters in textarea input were never being escaped, creating a potential for rendering artifacts in the diff output. The fix required using PHP chr(38) to construct the & character in the replacement strings, bypassing the entity-decoding behavior of the file editing tool. The corrected function now properly encodes & → &, < → <, > → >, and " → ". This was the root cause behind earlier rendering issues where special HTML elements in text content could confuse the browser's parser.
Dedup Panel Height Synchronization — syncDedupHeights() Implementation
The third mode (Dedup/Sort/Lines) had a UX defect: the read-only output textarea and editable input textarea could drift to different heights as content changed. Since dedupOutput is a readonly textarea, the input event doesn't fire on it, so the existing autoResize() function wasn't triggered. A new syncDedupHeights() function was implemented that calculates scrollHeight for both textareas after calling autoResize() on each, then sets both to Math.max(h1, h2) + 4px. This function is called in three scenarios: (1) after any operation writes to the output (setLines()), (2) when output is cleared (clearOutput()), and (3) on every input event from the input textarea. The result is that both textareas always maintain the same visual height, keeping the side-by-side layout aligned even as content grows or shrinks.
Default Tab Switch & Character Limit Enforcement
The default active tab was changed from Text Diff to Similarity (percentage overlap mode), reflecting the primary use case for the platform. Both the tab button's active class and the panel div's active class were switched. All six textarea elements across the three tool panels received a uniform maxlength="10000" attribute, capping input at 10,000 characters. This prevents the DP table in the LCS diff from growing to sizes that could cause browser lag on low-end devices, while still accommodating substantial text blocks (approximately 1,500-2,000 English words). The similarity checker's qualitative description system was refined from 5 coarse tiers to 11 granular tiers at 10-percentage-point intervals, providing more nuanced feedback for every possible score range.
June 5, 2026
Cosine Similarity Engine & Tabbed Three-Mode Interface
Cosine Similarity — TF Vectorization with Color-Coded Scoring Tiers
The cosine similarity engine was implemented using Term Frequency (TF) vectorization. The pipeline: (1) tokenize() lowercases text, strips punctuation via regex, and splits on whitespace to extract word tokens — with explicit CJK Unicode range support for Chinese text comparison. (2) termFrequency() builds sparse frequency maps for each text. (3) cosineSimilarity() constructs a shared vocabulary space, builds aligned vectors, and computes dot product ÷ (magnitude_A × magnitude_B). The result is displayed as a percentage (0–100%) with a color-coded progress bar: ≥90% dark green (nearly identical), ≥70% green (high), ≥40% yellow (moderate), below 40% red (low). A qualitative interpretation label and token counts for both texts are displayed for transparency. This cosine-based approach was chosen over Euclidean distance specifically because it normalizes for document length — a 500-word and 5,000-word text on the same topic can score high.
Three-Tab Interface — Diff, Similarity & Dedup/Sort/Lines
The tool interface was structured as a three-tab layout using CSS class-based visibility toggling (.text-tab-panel.active) with zero DOM removal, preserving textarea content when users switch between tabs. Tab 1 (Text Diff): side-by-side textareas with LCS-based line comparison, color-coded + added / - removed / unchanged output, and stats summary. Tab 2 (Similarity): two independent textareas feeding the TF-cosine pipeline, with a progress bar, percentage score, qualitative description, and token counts. Tab 3 (Dedup/Sort/Lines): input/output textarea pair with six action buttons (Deduplicate, Sort A→Z, Sort Z→A, Randomize, Line Numbers, Clear). Each tab button includes a Material Symbols icon (difference, percent, list_alt) for instant visual recognition. The active tab indicator uses a bottom-border accent with CSS transition for smooth visual feedback.
Textarea UX — Dedicated Input/Output Panels with Placeholder Guidance
The dedup panel was designed with separate input and output textareas rather than a single in-place editing field. This design choice enables: (1) users to compare before/after states side-by-side, (2) the output to be read-only (readonly attribute) preventing accidental edits, (3) users to chain operations (dedup → sort → number lines) by copying output back to input, and (4) clear visual separation between the raw data and processed result. Placeholder text guides users and the spellcheck="false" attribute prevents browser spell-check from underlining code, URLs, and structured data.
June 3, 2026
LCS Diff Implementation & Brand Transition to Text Tools
LCS Diff Algorithm — Dynamic Programming Line-by-Line Comparison
The text diff engine was built on the Longest Common Subsequence (LCS) dynamic programming algorithm. The lcsMatrix(a, b) function constructs a 2D DP table where dp[i][j] stores the LCS length between prefixes of length i and j. Each line is treated as an atomic element — the algorithm compares whole lines rather than individual characters, producing clean, readable diffs suitable for code review and document comparison. The backtrack(dp, a, b, i, j) function reconstructs the edit sequence from the DP table, classifying each line as same, added, or removed. The computeDiff() function renders the result with color-coded prefixes: green + for added lines, red - for removed, and space for unchanged. A stats bar summarizes total unchanged, added, and removed line counts. Time and space complexity is O(m×n) — efficient for documents up to several thousand lines in the browser.
CSS Component Design — Text Tools Visual Language
A complete CSS component system was designed for the three-tool interface. Key components include: .text-tabs-nav (horizontal tab button bar with active state indication), .text-tab-panel (visibility-toggled content areas preserving textarea state across tab switches), .diff-panels (responsive side-by-side layout collapsing to stacked on mobile), .diff-result (scrollable diff output with monospace font and color-coded line prefixes), .sim-bar-track and .sim-bar-fill (animated progress bar with color tiers), .dedup-panels (input/output textarea pair with action button grid), and .tool-action-btn (primary/secondary/ghost button variants with Material Symbols icon integration). All components use the 345tool design token system for visual consistency across the satellite site network.
Brand Transition — Rosenav from Password Checker to Text Tools Platform
The site was rebranded from a single-purpose password strength checker to a multi-tool text processing platform while maintaining the Rosenav brand name and rosenav.com domain. The header icon, Open Graph meta tags, Twitter Card tags, and all structured data blocks were updated to reflect the new tool set. The old password-checker.js (427 lines, entropy scoring, crack-time estimation, pattern detection, CSPRNG generator) was archived and replaced with text-tools.js (LCS diff, cosine similarity, dedup/sort/lines). The CSS delivery was optimized by merging tailwind.min.css and style.css into a single combined.css file. Google Analytics 4 was prepared with a placeholder measurement ID pending production deployment. The 345tool Team JSON-LD Organization block remained locked across all pages per satellite site matrix policy.
June 1, 2026
Algorithm Selection, Tokenizer Design & Zero-Server Architecture
Algorithm Selection — LCS, Cosine Similarity & Fisher-Yates with CSPRNG
Three core algorithms were selected through rigorous evaluation of alternatives. Text Diff: LCS dynamic programming was chosen over Myers' diff algorithm (which optimizes for edit distance minimality) and patience diff (which excels for code but is more complex). LCS provides the optimal balance of correctness, readability, and implementation clarity for a browser-based tool. The O(m×n) DP approach produces the same results as git diff's default mode while being straightforward to audit. Similarity: Cosine similarity with TF vectorization was selected over Jaccard similarity, Levenshtein distance, and n-gram overlap. Cosine similarity normalizes for document length and provides a continuous 0–1 score that is intuitive to interpret and widely understood in the NLP community. TF was preferred over TF-IDF to avoid the complexity of maintaining an IDF corpus in a client-side-only tool. Shuffling: Fisher-Yates with crypto.getRandomValues() was chosen over Math.random()-based shuffles to eliminate statistical biases inherent in LCG/Xorshift128+ generators — every permutation is equally probable with CSPRNG sourcing.
Tokenizer Design — Unicode-Aware with CJK Support
The tokenizer for the similarity engine was designed with explicit Unicode support. The regex pattern preserves CJK (Chinese/Japanese/Korean) characters in the U+4E00–U+9FFF range alongside Latin alphanumerics, enabling meaningful similarity comparison of Chinese-language texts. The tokenizer lowercases all input (case-insensitive comparison), strips punctuation and special characters, splits on whitespace boundaries, and filters empty tokens. This design handles mixed-language texts gracefully — an English paragraph with Chinese terms, or a bilingual document, will produce a combined token set reflecting both language contributions to the similarity score.
Zero-Server Architecture — Privacy by Design
The platform was architected from inception with a strict zero-server-footprint mandate. Every computational operation — LCS matrix construction and backtracking, tokenization and TF vectorization, cosine similarity computation, hash-set deduplication, locale-aware sorting, Fisher-Yates CSPRNG shuffling, and line number generation — executes exclusively within the user's browser as vanilla JavaScript with zero external dependencies. No text content, no diff results, no similarity scores, no dedup statistics, and no behavioral telemetry ever leave the device. This architecture is not merely a privacy preference; for a text processing tool that handles potentially sensitive content (proprietary source code, legal documents, unpublished manuscripts, business data), any server-side processing would constitute an unacceptable data exposure risk. The tool is fully functional offline after the initial page load, requiring no network connectivity for any core operation.
Contact
— E-mail: [email protected]
— Date of creation: June 1, 2026 • Last updated: June 13, 2026

We are the 345tool Team
345tool is an independent developer collective engineering elite, pure client-side, and privacy-first web utilities to replace bloated internet tools.